我们的研究
MultiConIR: Towards Multi-Condition Information Retrieval
EMNLP 2025 Findings
·
04 Sep 2025
·
arxiv:2503.08046v3
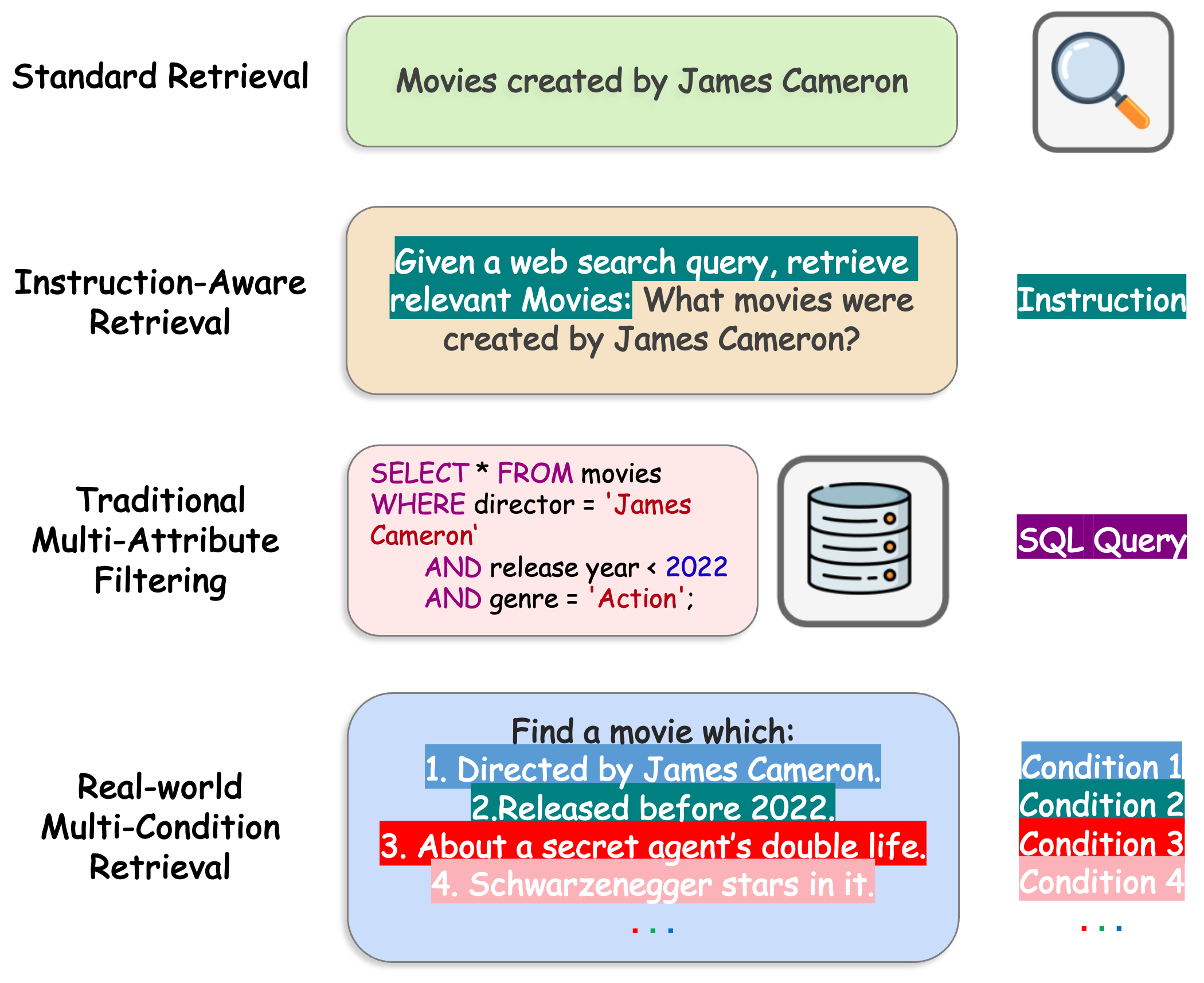
Multi-condition information retrieval (IR) poses a significant yet underexplored challenge. We introduce MultiConIR, a benchmark for evaluating retrieval and reranking models under nuanced multi-condition queries across five domains. The benchmark examines three dimensions—complexity robustness, relevance monotonicity, and query format sensitivity. Experiments on 15 models reveal severe degradation as query complexity grows, with failures to maintain monotonicity and high sensitivity to query style and condition placement. The strong performance of GPT-4o highlights the gap between current IR systems and advanced LLMs. Our analysis further identifies factors behind reranker deterioration and the impact of condition positioning, offering insights for advancing IR systems in complex search scenarios.
Multimodal Language Models See Better When They Look Shallower
EMNLP 2025
·
30 Apr 2025
·
arxiv:2504.21447
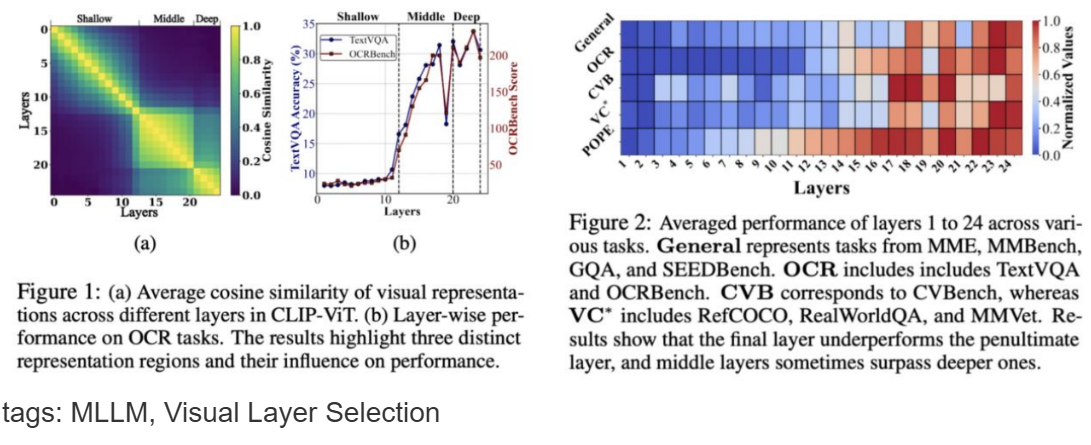
Multimodal large language models (MLLMs) have achieved impressive performance across a wide range of tasks, typically using CLIP-ViT as their visual encoder due to its strong text-image alignment capabilities. While prior studies suggest that different CLIP-ViT layers capture different types of information, with shallower layers focusing on fine visual details and deeper layers aligning more closely with textual semantics, most MLLMs still select visual features based on empirical heuristics rather than systematic analysis. In this work, we propose a Layer-wise Representation Similarity approach to group CLIP-ViT layers with similar behaviors into {shallow, middle, and deep} categories and assess their impact on MLLM performance. Building on this foundation, we revisit the visual layer selection problem in MLLMs at scale, training LLaVA-style models ranging from 1.4B to 7B parameters. Through extensive experiments across 10 datasets and 4 tasks, we find that: (1) deep layers are essential for OCR tasks; (2) shallow and middle layers substantially outperform deep layers on reasoning tasks involving counting, positioning, and object localization; (3) a lightweight fusion of features across shallow, middle, and deep layers consistently outperforms specialized fusion baselines and single-layer selections, achieving gains on 9 out of 10 datasets. Our work offers the first principled study of visual layer selection in MLLMs, laying the groundwork for deeper investigations into visual representation learning for MLLMs.
VisiPruner: Decoding Discontinuous Cross-Modal Dynamics for Efficient Multimodal LLMs
EMNLP 2025
·
04 Sep 2025
·
/
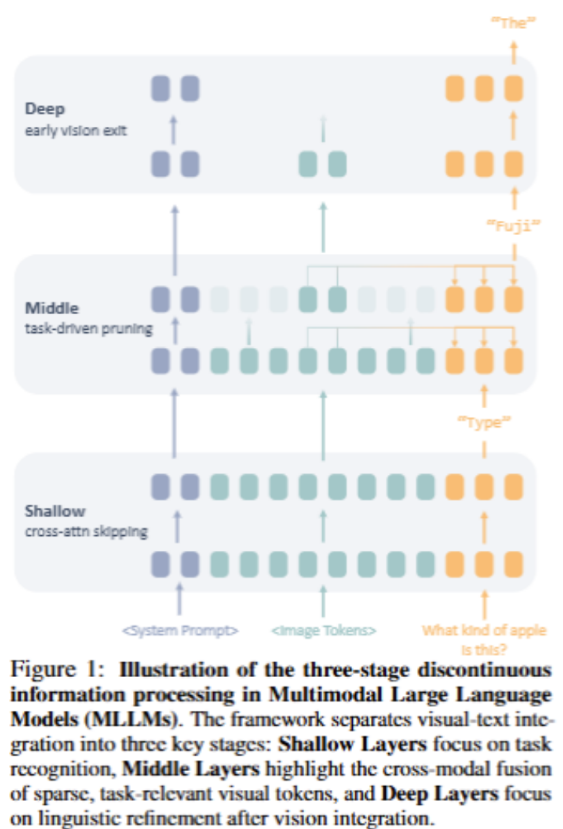
Multimodal Large Language Models (MLLMs) have achieved impressive performance on vision–language tasks, yet the quadratic growth of attention computation with respect to multimodal tokens incurs significant computational overhead. Although prior studies have explored token pruning in MLLMs, a fundamental understanding of how these models process and integrate multimodal information remains lacking. Through systematic analysis, this work reveals a three-stage process of cross-modal interaction in MLLMs: (1) in the shallow layers, the model primarily identifies task intent, with visual tokens acting as passive attention absorbers; (2) in the middle layers, cross-modal fusion occurs abruptly and is driven by a small set of key visual tokens; (3) in the deep layers, visual tokens are gradually discarded, and the model focuses solely on fine-grained linguistic processing. Building on these insights, we propose VisiPruner, a training-free dynamic pruning framework that reduces up to 99% of vision-related attention computation and 62.8% of FLOPs while preserving model performance. Moreover, VisiPruner demonstrates strong generalization across various MLLMs. Beyond pruning, our findings provide actionable guidance for training future efficient MLLMs, suggesting that aligning model architectures with their hierarchical processing dynamics can substantially improve efficiency.
PricingLogic: Evaluating LLMs Reasoning on Complex Tourism Pricing Tasks
EMNLP 2025
·
04 Sep 2025
·
/
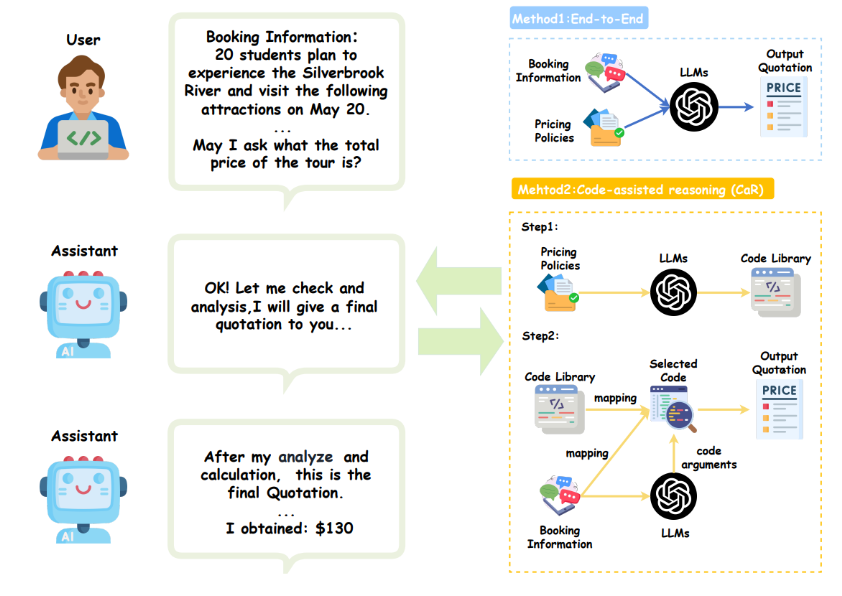
We present PricingLogic, the first benchmark designed to evaluate whether Large Language Models (LLMs) can reliably automate tourism-booking prices under multiple, overlapping fare rules. Travel agencies are eager to delegate this error-prone task to AI systems; however, deploying LLMs without verified reliability risks substantial financial losses and undermines customer trust. PricingLogic consists of 300 natural-language booking requests derived from 42 real-world pricing policies, covering two levels of difficulty: (i) basic customer-type pricing and (ii) bundled-tour calculations involving interacting discounts. Evaluations across a range of LLMs reveal a sharp performance decline on the more challenging tier, exposing systematic weaknesses in rule interpretation and arithmetic reasoning. These findings underscore that, despite their broad capabilities, current LLMs remain unreliable for revenue-critical applications without additional safeguards or domain-specific adaptation.
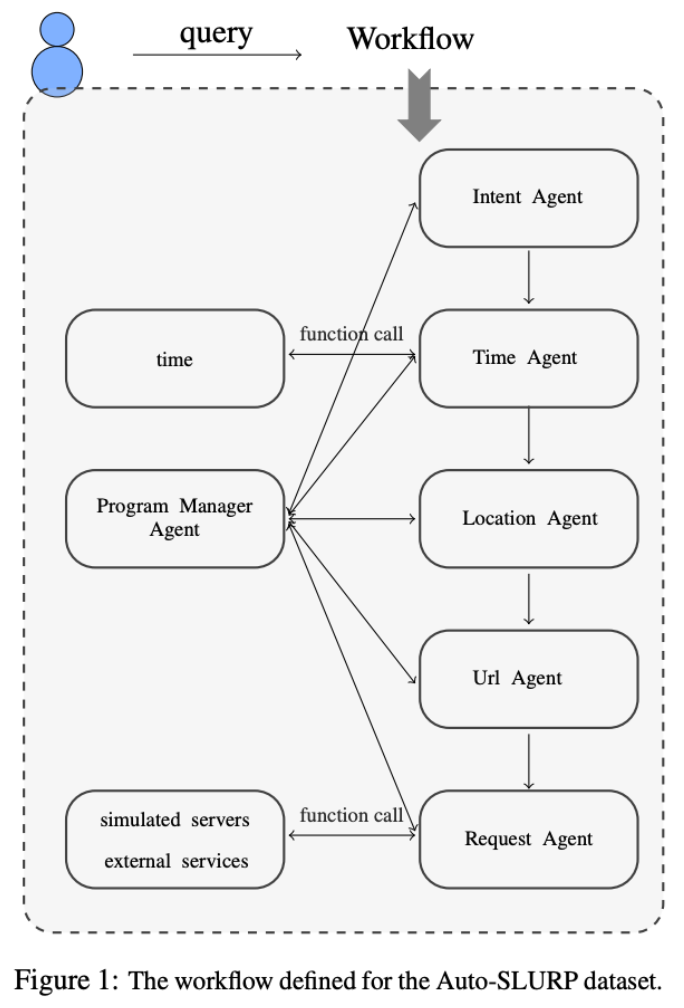
Auto-SLURP: A Benchmark Dataset for Evaluating Multi-Agent Frameworks in Smart Personal Assistant
EMNLP 2025 Findings
·
25 Apr 2025
·
arxiv:2504.18373
In recent years, multi-agent frameworks powered by large language models (LLMs) have advanced rapidly. Despite this progress, there is still a notable absence of benchmark datasets specifically tailored to evaluate their performance. To bridge this gap, we introduce Auto-SLURP, a benchmark dataset aimed at evaluating LLM-based multi-agent frameworks in the context of intelligent personal assistants. Auto-SLURP extends the original SLURP dataset – initially developed for natural language understanding tasks – by relabeling the data and integrating simulated servers and external services. This enhancement enables a comprehensive end-to-end evaluation pipeline, covering language understanding, task execution, and response generation. Our experiments demonstrate that Auto-SLURP presents a significant challenge for current state-of-the-art frameworks, highlighting that truly reliable and intelligent multi-agent personal assistants remain a work in progress.
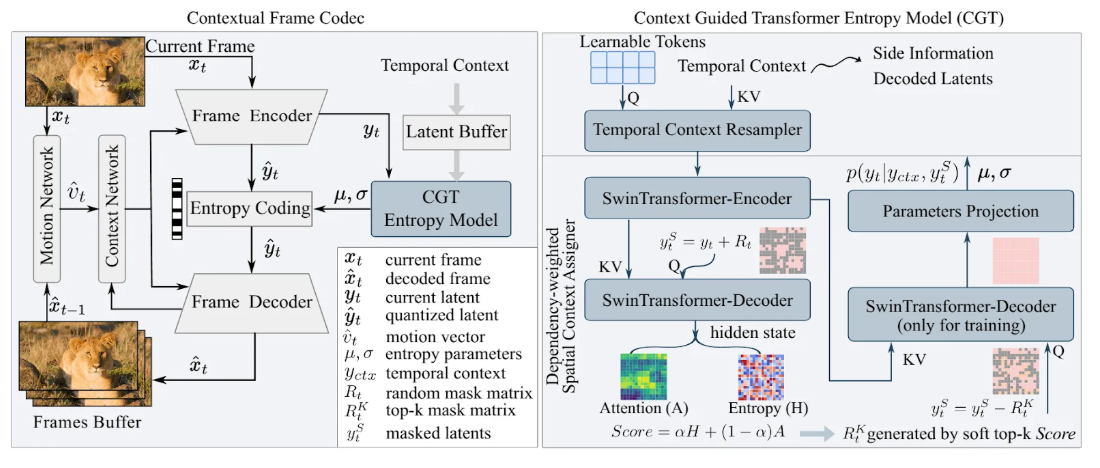
Context Guided Transformer Entropy Modeling for Video Compression
ICCV 2025
·
03 Aug 2025
·
arxiv:2508.01852
The entropy model is a critical component in video compression, as it determines the coding efficiency by estimating the probability distribution of quantized latent representations. A key challenge in entropy model lies in effectively capturing and utilizing contextual information, including temporal and spatial contexts, to accurately estimate the probability mass functions (PMFs) of video frames. This work introduces a Context Guided Transformer (CGT) entropy model, which leverages a temporal context resampler to distill long-range temporal cues into fixed-length representations and a dependency-weighted spatial context assigner to selectively model spatial dependencies in a structured order. By jointly addressing temporal and spatial context utilization, our approach achieves improved compression performance while significantly reducing computational overhead.
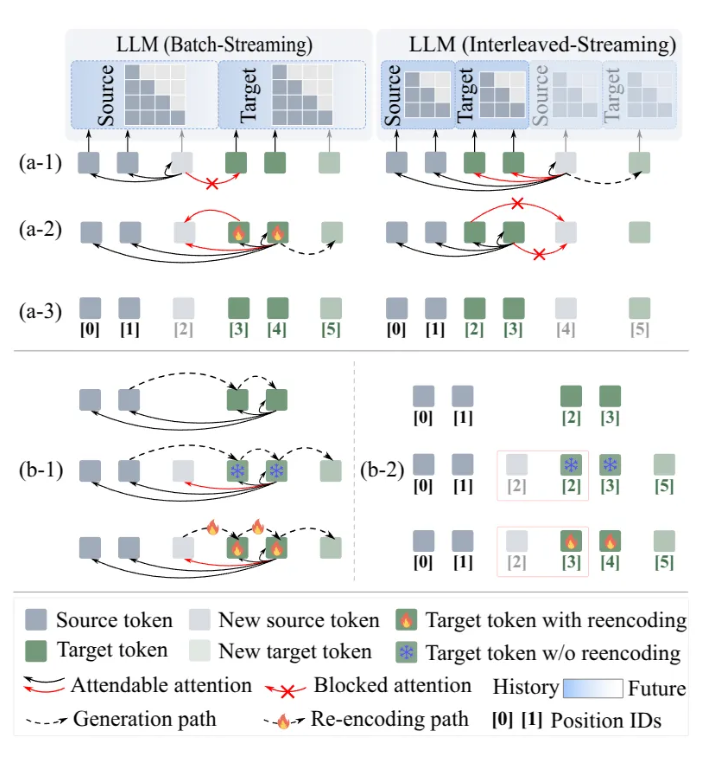
LLM as Effective Streaming Processor: Bridging Streaming-Batch Mismatches with Group Position Encoding
EMNLP 2025 Findings
·
29 May 2025
·
arxiv:2505.16983
Large Language Models (LLMs) are primarily designed for batch processing. Existing methods for adapting LLMs to streaming rely either on expensive re-encoding or specialized architectures with limited scalability. This work identifies three key mismatches in adapting batch-oriented LLMs to streaming: (1) input-attention, (2) output-attention, and (3) position-ID mismatches. While it is commonly assumed that the latter two mismatches require frequent re-encoding, our analysis reveals that only the input-attention mismatch significantly impacts performance, indicating re-encoding outputs is largely unnecessary. To better understand this discrepancy with the common assumption, we provide the first comprehensive analysis of the impact of position encoding on LLMs in streaming, showing that preserving relative positions within source and target contexts is more critical than maintaining absolute order. Motivated by the above analysis, we introduce a group position encoding paradigm built on batch architectures to enhance consistency between streaming and batch modes. Extensive experiments on cross-lingual and cross-modal tasks demonstrate that our method outperforms existing approaches. Our method requires no architectural modifications, exhibits strong generalization in both streaming and batch modes.
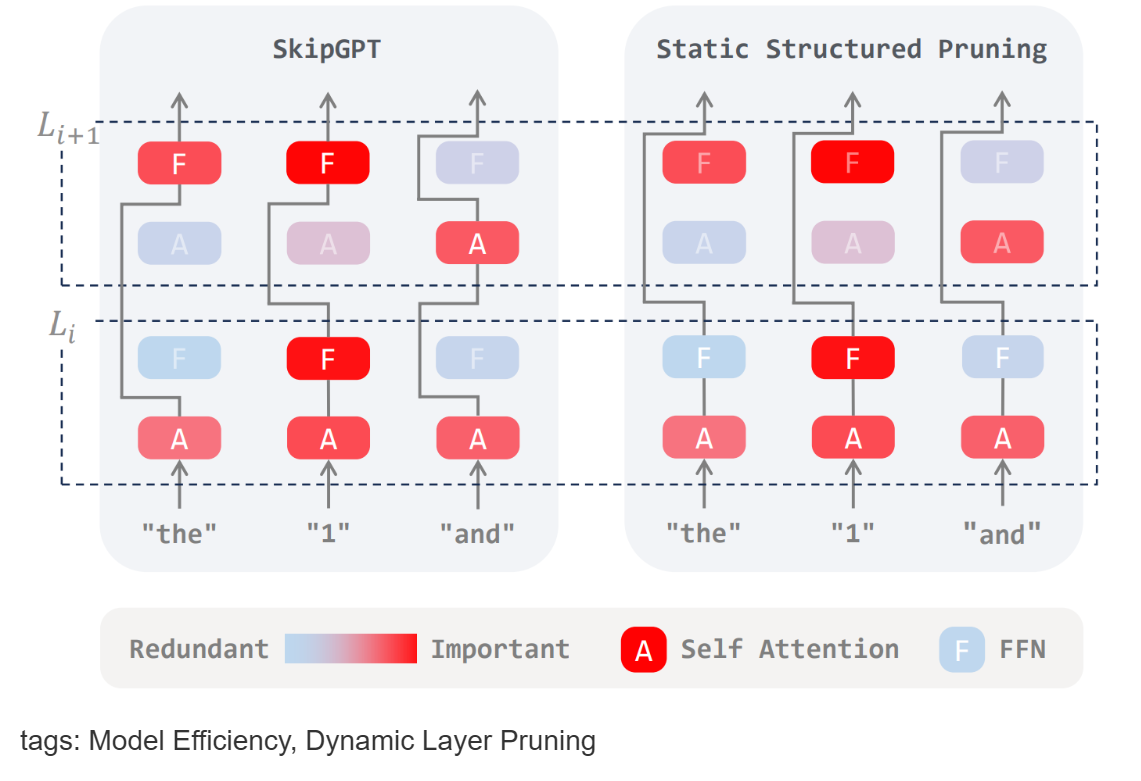
SkipGPT: Each Token is One of a Kind
ICML 2025
·
04 Jan 2025
·
arxiv:2506.04179
Large Language Models (LLMs) deliver impressive performance but at high computational cost. SkipGPT introduces a dynamic layer pruning framework that improves efficiency by combining token-aware routing with differentiated pruning strategies for MLP and attention layers. To ensure stability, it adopts a two-stage optimization process: learning routing policies first, then restoring performance through lightweight fine-tuning. Experiments show SkipGPT reduces parameters by over 40% while maintaining or surpassing the original model’s accuracy, offering a practical path toward scalable and resource-efficient LLM deployment.
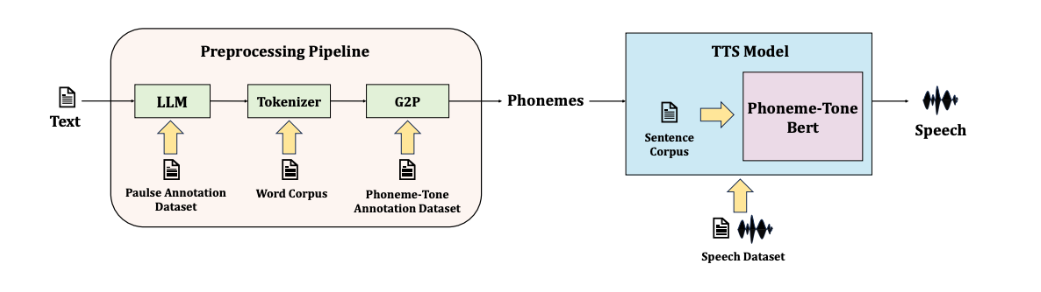
Scaling Under-Resourced TTS: A Data-Optimized Framework with Advanced Acoustic Modeling for Thai
ACL 2025 (Industry Track)
·
10 Apr 2025
·
arxiv:2504.07858
Text-to-speech (TTS) technology has achieved impressive results for widely spoken languages, yet many under-resourced languages remain challenged by limited data and linguistic complexities. In this paper, we present a novel methodology that integrates a data-optimized framework with an advanced acoustic model to build high-quality TTS systems for low-resource scenarios. We demonstrate the effectiveness of our approach using Thai as an illustrative case, where intricate phonetic rules and sparse resources are effectively addressed. Our method enables zero-shot voice cloning and improved performance across diverse client applications, ranging from finance to healthcare, education, and law. Extensive evaluations—both subjective and objective—confirm that our model meets state-of-the-art standards, offering a scalable solution for TTS production in data-limited settings, with significant implications for broader industry adoption and multilingual accessibility.
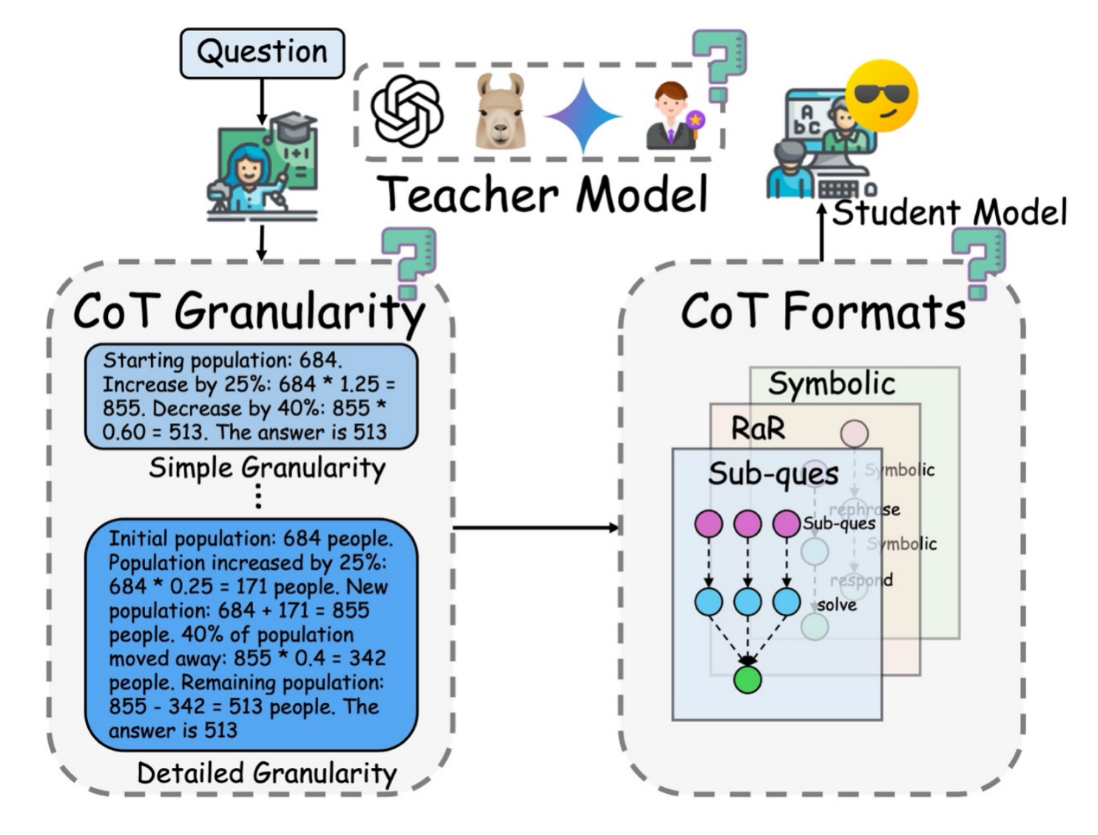
Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
ACL 2025 Findings
·
27 May 2025
·
arxiv:2502.18001
Large Language Models (LLMs) achieve strong reasoning via Chain-of-Thought (CoT) prompting, but at high computational cost, motivating CoT distillation into Small Language Models (SLMs). This work examines how granularity, format, and teacher choice affect CoT distillation through experiments on four teachers, seven students, and seven reasoning benchmarks. We find: (1) SLMs show a non-monotonic response to granularity—stronger models prefer finer reasoning, weaker ones simpler supervision; (2) CoT format strongly influences LLMs but barely affects SLMs; (3) Stronger teachers do not always yield better students, as diversity and complexity can outweigh accuracy. These results highlight the need to tailor CoT strategies to student models, offering practical guidance for SLM distillation.
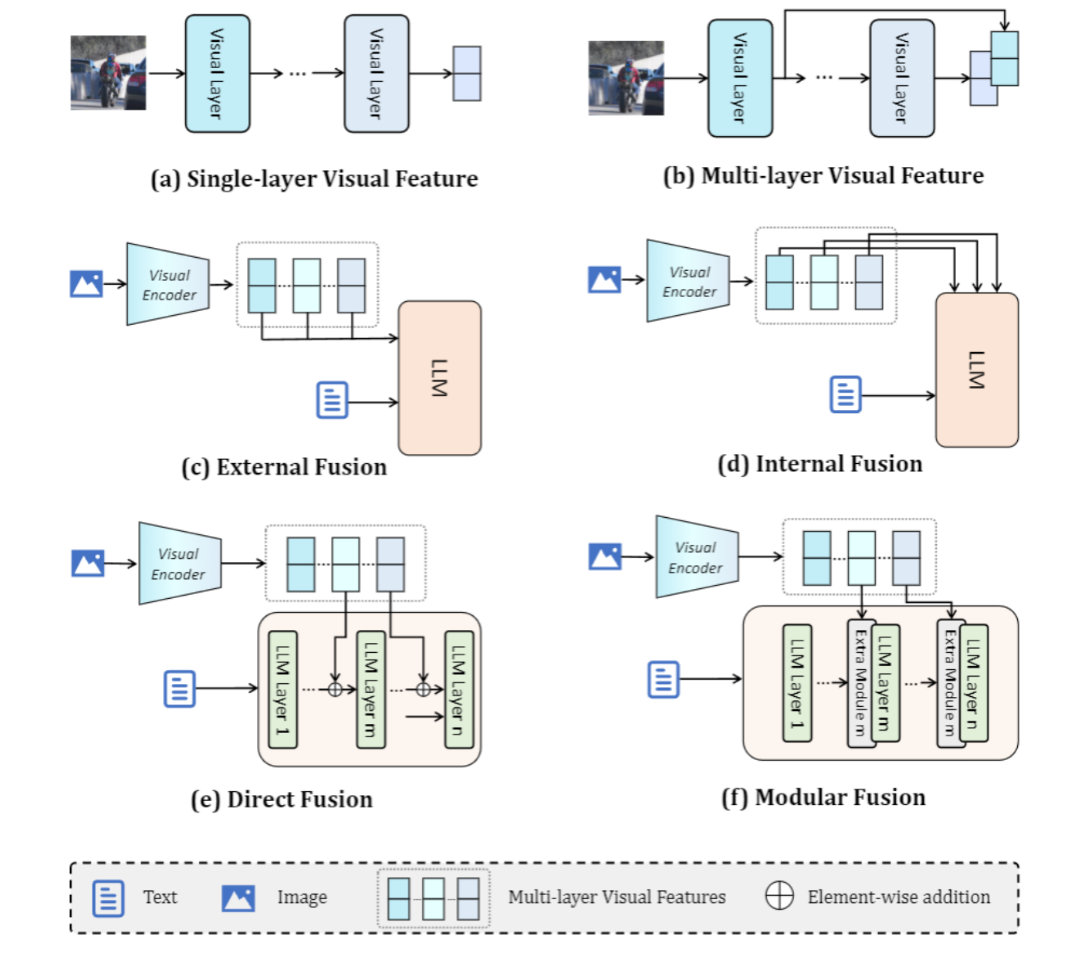
Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
CVPR 2025
·
08 Mar 2025
·
arxiv:2503.06063
Multimodal Large Language Models (MLLMs) have made significant advancements in recent years, with visual features playing an increasingly critical role in enhancing model performance. However, the integration of multi-layer visual features in MLLMs remains underexplored, particularly with regard to optimal layer selection and fusion strategies. Existing methods often rely on arbitrary design choices, leading to suboptimal outcomes. In this paper, we systematically investigate two core aspects of multi-layer visual feature fusion: (1) selecting the most effective visual layers and (2) identifying the best fusion approach with the language model. Our experiments reveal that while combining visual features from multiple stages improves generalization, incorporating additional features from the same stage typically leads to diminished performance. Furthermore, we find that direct fusion of multi-layer visual features at the input stage consistently yields superior and more stable performance across various configurations.
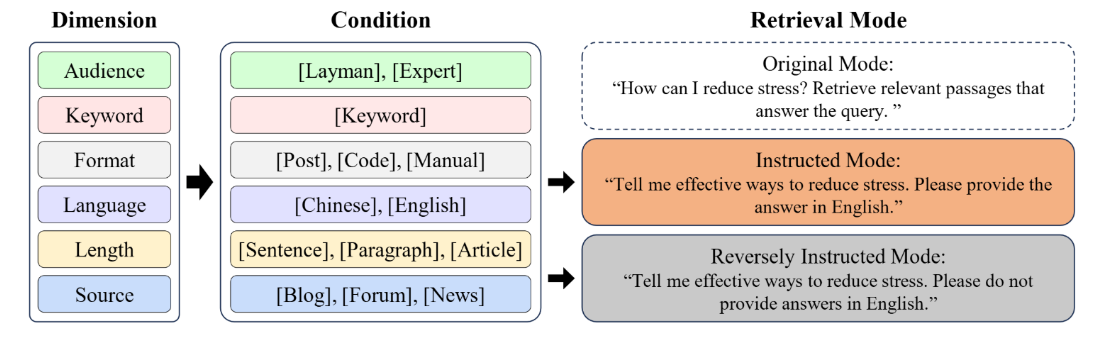
Beyond Content Relevance: Evaluating Instruction Following in Retrieval Models
ICLR 2025
·
05 Mar 2025
·
arxiv:2410.23841
Instruction-following capabilities in LLMs have progressed significantly, enabling more complex user interactions through detailed prompts. However, retrieval systems have not matched these advances, most of them still relies on traditional lexical and semantic matching techniques that fail to fully capture user intent. Recent efforts have introduced instruction-aware retrieval models, but these primarily focus on intrinsic content relevance, which neglects the importance of customized preferences for broader document-level attributes. This study evaluates the instruction-following capabilities of various retrieval models beyond content relevance, including LLM-based dense retrieval and reranking models. We develop InfoSearch, a novel retrieval evaluation benchmark spanning six document-level attributes: Audience, Keyword, Format, Language, Length, and Source, and introduce novel metrics – Strict Instruction Compliance Ratio (SICR) and Weighted Instruction Sensitivity Evaluation (WISE) to accurately assess the models’ responsiveness to instructions. Our findings indicate that although fine-tuning models on instruction-aware retrieval datasets and increasing model size enhance performance, most models still fall short of instruction compliance.
–>