Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
Authors: Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, Dietrich Klakow
论文地址:https://arxiv.org/pdf/2404.14122
代码:https://github.com/uds-lsv/mt-sft
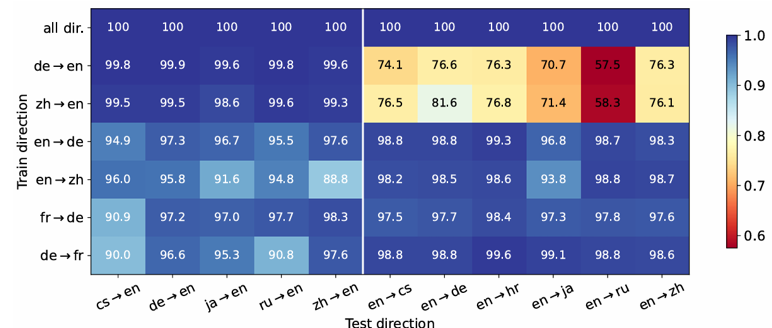
论文简介:传统上,多语言机器翻译的成功归因于训练数据的三个关键因素:大规模数据量、多样化的翻译方向以及高质量的数据。在当前微调大语言模型(LLMs)以进行翻译的实践中,我们重新审视了这些因素的重要性。我们现,LLMs 在仅微调 32 对平行句子的情况下就表现出了强大的翻译能力,并且微调单一翻译方向能够实现多方向的翻译。然而,方向的选择至关重要:仅使用英文作为目标语言进行微调可能导致任务误解,从而阻碍向非英语语言的翻译。当噪声合成数据作为目标语言时,特别是当目标语言在 LLM 预训练中已得到良好表示的情况下,也会出现问题。然而,值得注意的是,合成数据对一个在预训练中代表性较低的语言的影响较为轻微。我们的研究结果表明,在将 LLMs 适配于翻译任务时,对数据量的要求可以适当放宽,但仍需仔细考虑,以防止 LLM 利用非预期的数据偏差。